How Spinnaker Fits into the Continuous Delivery Puzzle
17 Jan 2018This post was originally published at the Armory Blog. Reposting here since it is not available there any more.
Introduction
When a new tool appears in the IT landscape, users have the natural tendency to compare the tool to existing solutions. This is an understandable reaction because we tend to build on existing knowledge and then “fit” new tools into what we already know.
Comparing new and old concepts is great for elevator pitches. Product X comes out, and people describe it as “a direct competitor to product Y but with certain improvements in area Z”. This statement allows users to understand the scope and goal of Product X in a single sentence (provided they are already familiar with its direct competitor.)
However, not all tools are created as direct competitors to something else. Every now and then, a new tool arrives that attempts to push the envelope one step further. Instead of improving an existing aspect of a workflow, the new tool calls for a paradigm shift.
Spinnaker is a tool that has no direct competitor and expects a mindset change from its users. In a world where developers discuss build servers, configuration management tools, cluster orchestrators & cloud consoles, Spinnaker redefines the basic concepts. This redefinition is done in a much higher abstraction level – in a way that simply did not exist before.
In this article, we will see how Spinnaker fits into the Continuous Delivery puzzle and why it is different than all the tools before it. If you insist on direct comparisons, feel free to consult our comparison of Spinnaker versus other solutions first.
The basic software life-cycle
If you look at any software application from 10,000 feet the basic lifecycle is the following:
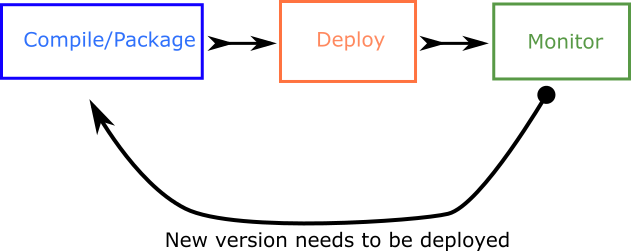
The phases are:
- The software must be packaged in its final binary form
- The binary is copied to the machine that will run it
- The application is executed and after it becomes healthy it is continuously monitored
- Whenever a new version of the application is created, the cycle starts from the beginning
Traditionally the phases of this cycle could take several hours or even days. In the case of physical datacenters the deploy phase could even take months if the machine responsible for the software was not ready at the time of installation.
Thankfully cloud infrastructure has (first in the form of Virtual Machines and lately with containers) removed all barriers that arose from the use of physical machines. Creating a new machine is now possible in a manner of minutes or even seconds.
This has allowed fast-moving companies to minimize the feedback time of the basic software cycle. The result being multiple software releases every hour as opposed to traditional releases that would happen weekly or monthly.
Deploying an application very often is a huge advantage for the business owners of the application because it means that new features reach the application users in the most timely manner. Unfortunately, the frequent releases also strain the development and operations teams responsible for the application. The previous picture is too abstract, and a better look at what happens in reality is shown below:
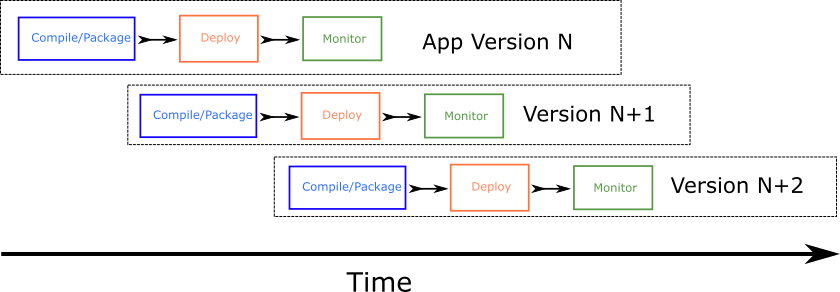
There is not a “single” application cycle anymore. At any given point in time, there are at least three versions of the application:
- The application that is already running in production and must stay healthy at all costs
- The application that is waiting to be deployed. It may even be partially deployed into a subset of machines (canaries)
- The application that developers are working on and will soon by released
In well-disciplined companies, more versions of the application might be present at any given time. For example, another version could exist that is currently passing load testing.
Moving from the the data-center to the cloud
Minimizing the length of the application lifecycle is a constant effort. Getting quickly new features in production is the ultimate goal of every software company. We have seen in the previous section that deployments are a crucial part of the length of the cycle making them one of most usual bottlenecks.
In fact, if we take a vertical slice of time in the application lifecycle from the previous picture, we can see that all 3 phases happen essentially at the same time. Even though each phase is for a different version, it should be clear that deployments are now an intrinsic component of the whole cycle. At any single point of time:
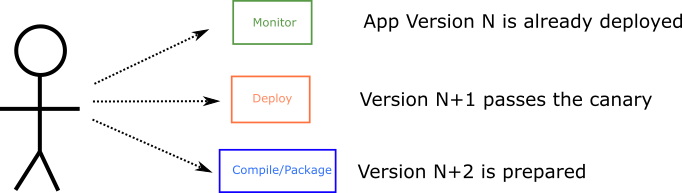
This new reality has caught a lot of companies off-guard. Traditionally, deployments were something that required special attention, happened infrequently, and usually required several manual steps. The problem of slow and error-prone deployments became even more apparent as companies moved their applications to public and private clouds.
Companies that still treat deployments as something exceptional that needs special attention have discovered that moving to the cloud is not as easy as changing the physical machines with virtual ones. After moving to the cloud, several companies discovered that deployments are now the bottleneck of each release cycle. Even if developers can implement features as fast as possible, problematic deployments will always prevent those features from reaching the application users.
Tools that help the development part of the cycle, can still work just fine in a cloud environment. Build servers and build systems that are responsible for preparing the application binary are still applicable even when the application is destined for the cloud.
On the other hand, deploying the application is a completely different problem and all techniques that deal with physical servers are mostly obsolete when it comes to virtual machines.
Obviously, a new solution is needed when it comes to cloud deployments.
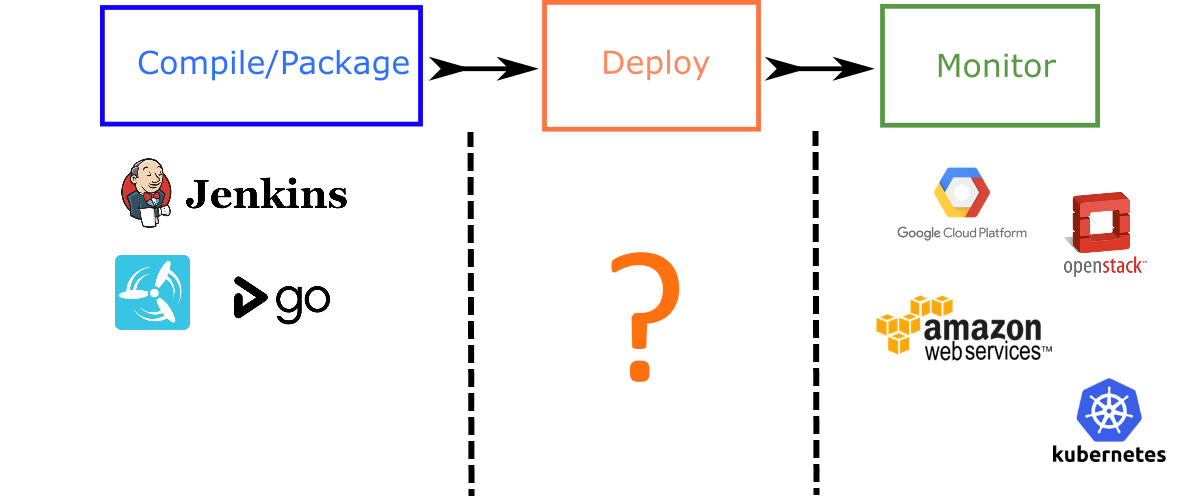
For the compilation phase, developers can still use the platforms they know and love. For example, Jenkins is a very powerful build server that is responsible for compiling and packaging the application binary, regardless of the final target of the application.
Public clouds like Amazon, Google, Microsoft, etc. already offer cloud consoles that show the status of each virtual machine. Kubernetes clusters come with their own handy dashboard that allows everybody to quickly glance at the status of each machine.
But what happens in the middle? How is the application actually deployed to the cloud?
Deployment scripts - the dark ages of cloud delivery
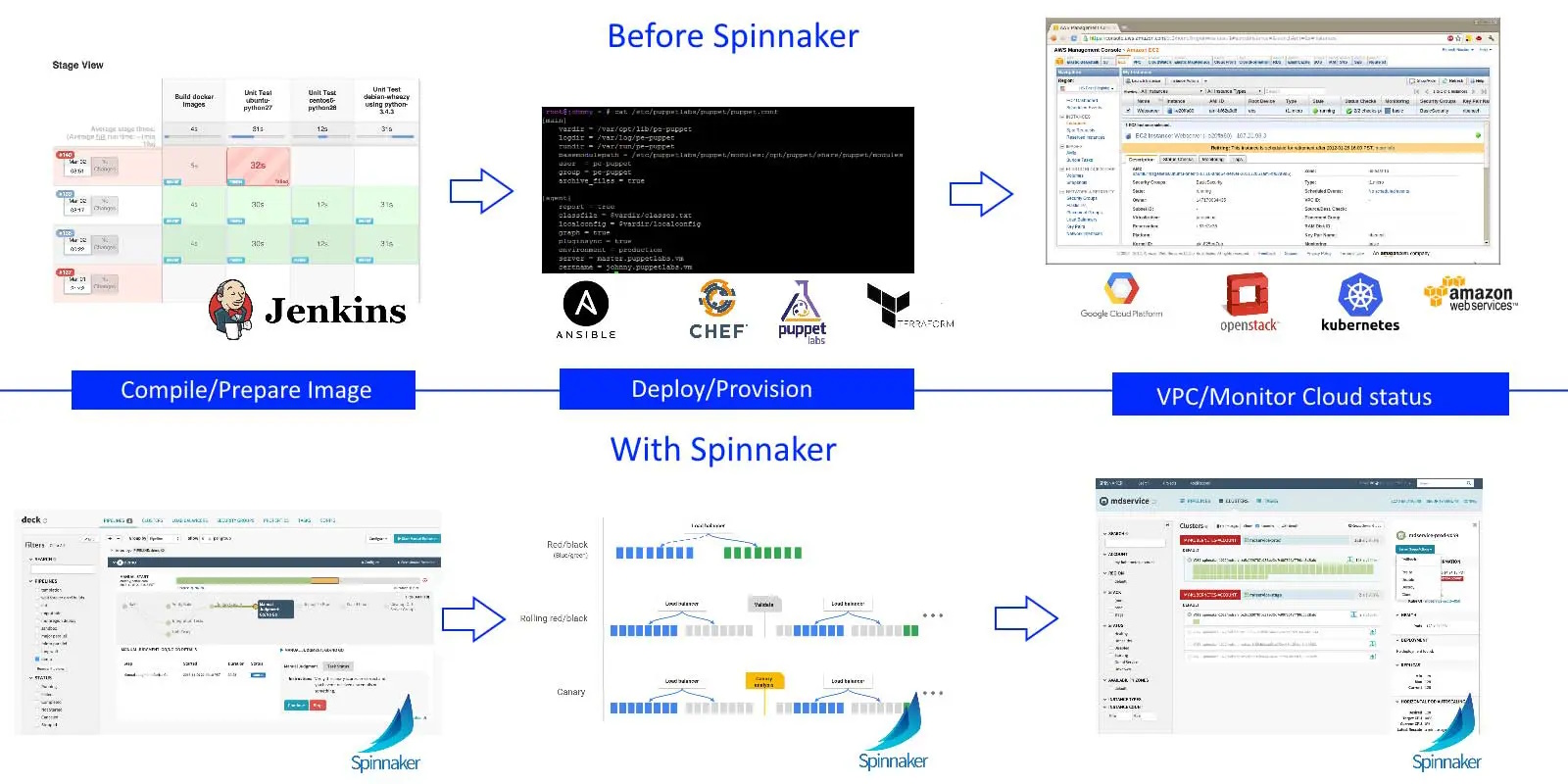
When it comes to cloud deployments, most companies followed the path of least resistance. They just extended their existing tools to handle the new paradigm of virtual machines:
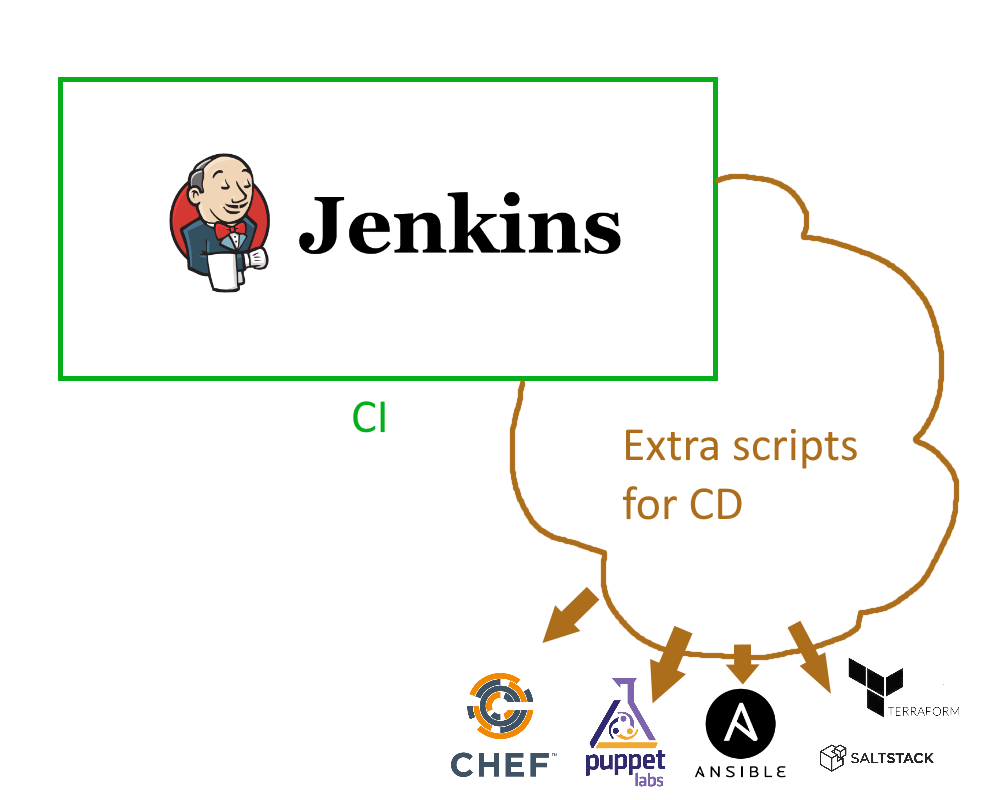
The picture above shows one of the classic patterns of cloud adoption within companies that had already physical servers.
- Jenkins is still used for compilation, but it now extended with extra jobs that handle deployment
- Configuration managements tools (e.g. Puppet and Chef) are now tasked with application deployment
- Custom scripts serve as glue code that brings the end result of Jenkins to what cloud APIs expect
This workflow is the result of “patching” existing tools with the new requirements of cloud development. Even though this technique can work in a limited manner for small teams, it quickly shows its shortcomings in big companies with a large number of applications.
Jenkins was never designed with deployment capabilities in mind. Its basic construct is a job and nothing else. It knows nothing about environments or deployments. Mixing compilation and deployment jobs quickly becomes a mess. Jenkins is used as an example here, but any traditional build server suffers from the same issues.
Puppet, Chef and similar tools were designed for system administration and not application deployment. They are perfect for setting up a machine and changing its configuration to a new state. Attempting to use them for application deployment is a losing battle. Their fire-and-forget nature is a huge obstacle when it comes to safe deployments. Rolling back a release is a nightmare if the main application deployment fails. Configuration drift is a constant problem and can ruin deployments in the most unpredicable manner.
The truth is that custom deployments scripts are essentially abusing all the existing tools (e.g. Jenkins and Chef/Puppet). They were never designed for cloud deployment in the first place. Any big company that tries this pattern will quickly see the limitations:
- The custom deployment scripts are handled by a specialized team with tribal knowledge
- Debugging a failing deployment is very hard due to all the moving parts
- Rollbacks are next to impossible and require heavy manual intervention
- Deployments are stressful because rollbacks are hard
- Unplanned downtime is constantly happening either because of bad releases or unsuccessful rollbacks
Instead of writing custom deployment scripts, a better solution would be to adopt a cloud-native tool specifically designed to handle deployments and rollbacks. Enter Spinnaker!
Embracing immutable infrastructure with Spinnaker
We have seen in the previous section the problems that appear when a company attempts to adapt datacenter tools for cloud deployments.
The main issue here, is that most existing tools are centered around the concept of mutable infrastructure. A physical server is used to deploy the initial version of an application and any new version that appears is layered on top of the existing server filesystem.
This solution might work well with physical servers, but with a cloud server there is an alternative option. We can instead create a completely new server on-the-fly when a new application version is created. This makes deployments (redirect traffic from old server to new server), canaries (keep both old and new server running) and rollbacks (destroy new server) very easy. Rollbacks in particular can now happen in a completely automated manner without any human intervention.
The benefits of immutable infrastructure are explained also in the CNCF glossary
Once we understand why immutable infrastructure is the way forward, it becomes apparent why adapting existing tools is problematic when it comes to cloud deployments.
Most (if not all) configuration management tools are designed for mutable infrastructure. This makes them a bad fit for cloud deployments that want to use immutable infrastructure.
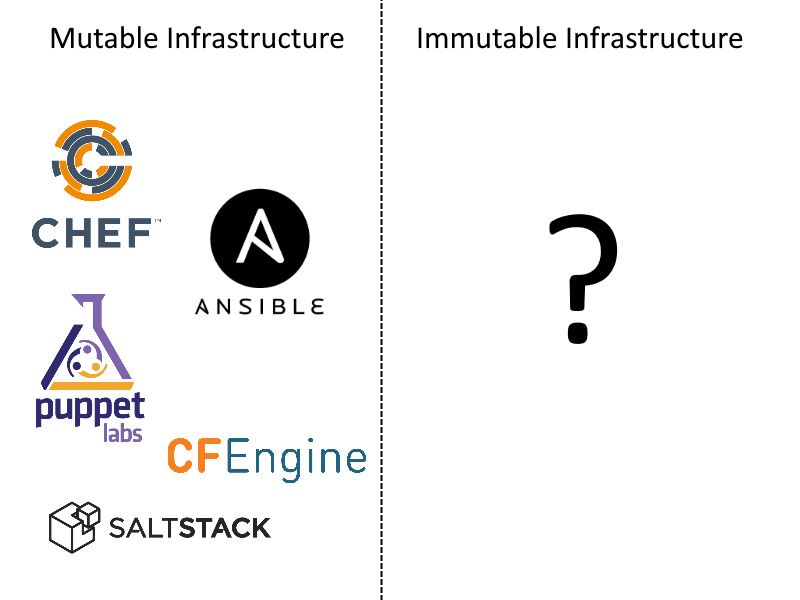
The truth is that all configuration management tools deploy applications in a destructive manner. They take an existing server, perform several changes and leave it in a different state. The old application is gone. Forever. A rollback is the reverse process of bringing that state back. This means that if there are a hundred things that can go wrong with a deployment, there are also a hundred things that can go wrong with the rollback itself.
A quick note about Terraform
Terraform is one of the newer tools that has gained a lot of traction lately for deployment automation. Even though at first glance terraform has adopted immutable infrastructure, in reality terraform is a low level solution destined towards the network constructs (e.g. load balancers) instead of application deployment. It does not support any kind of red/black deployment or canary states.
Netflix saw this need for a dedicated tool to handle cloud deployments in a native manner. Spinnaker is the first and (currently) only tool that fully embraces immutable infrastructure.
![]()
Spinnaker was used internally by Netflix and was recently open-sourced as a community project. It is already used in production by major companies and has contributors from major cloud providers. Spinnaker also works great with Kubernetes clusters (support was added by Google itself).
Cloud deployments with Spinnaker
We have already described the basic software lifecycle at the beginning of this article. Let’s unpack what Spinnaker does differently for each phase.
First of all, for compilation/packaging Spinnaker just delegates to Jenkins. Spinnaker is not a build server and does not want to be a build server. Using the standard Jenkins API, Spinnaker can start Jenkins jobs, monitor their progress and obtain their results.
The difference here is the inversion of control. Spinnaker is controlling the main pipeline and Jenkins is just one of the build steps. This keeps the scope of Jenkins contained at what it is doing best - compiling code. All compilation jobs still stay with Jenkins but the deployment responsibility stay with Spinnaker.

This pattern comes in contrast with the custom Jenkins script described in the previous section, where Jenkins is controlling the build and has special jobs for application deployment.
With the compilation phase out of the way, the next phase is deployment. This is the part where Spinnaker really shines. Spinnaker has built-in support for basic (rolling deploys) and advanced deployments (red/black) . This support is created in a standardized way without the need of special code or custom glue scripts.
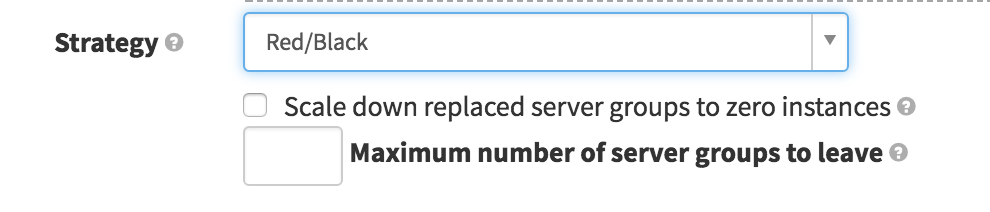
This means that by using Spinnaker you’re going to get, for free, the deployment patterns used by Netflix that allow for minimal (even zero) downtime when a new application is released.
With immutable infrastructure, rollbacks are also very easy. Again, Spinnaker has native support for rollbacks. Rollbacks in Spinnaker are literally a single button push.
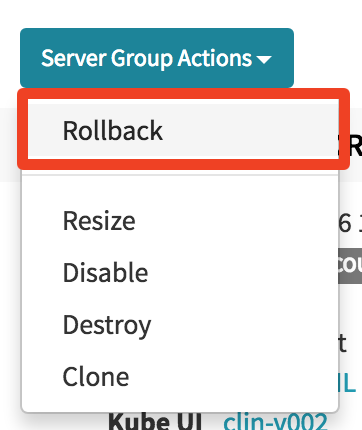
The capability to rollback a cluster is so easy, because Spinnaker has high-level knowledge for every cloud environment. Clusters, load balancers and security groups are natively modeled in Spinnaker.
The end result is a build pipeline within Spinnaker that is much more rich than a pure Jenkins pipeline. Creating a cluster, deploying and resizing are native steps instead of custom Jenkins jobs that call external scripts. All the familiar capabilities (e.g. manual approval, parallel steps) that developers expect from pipelines are also offered by Spinnaker.
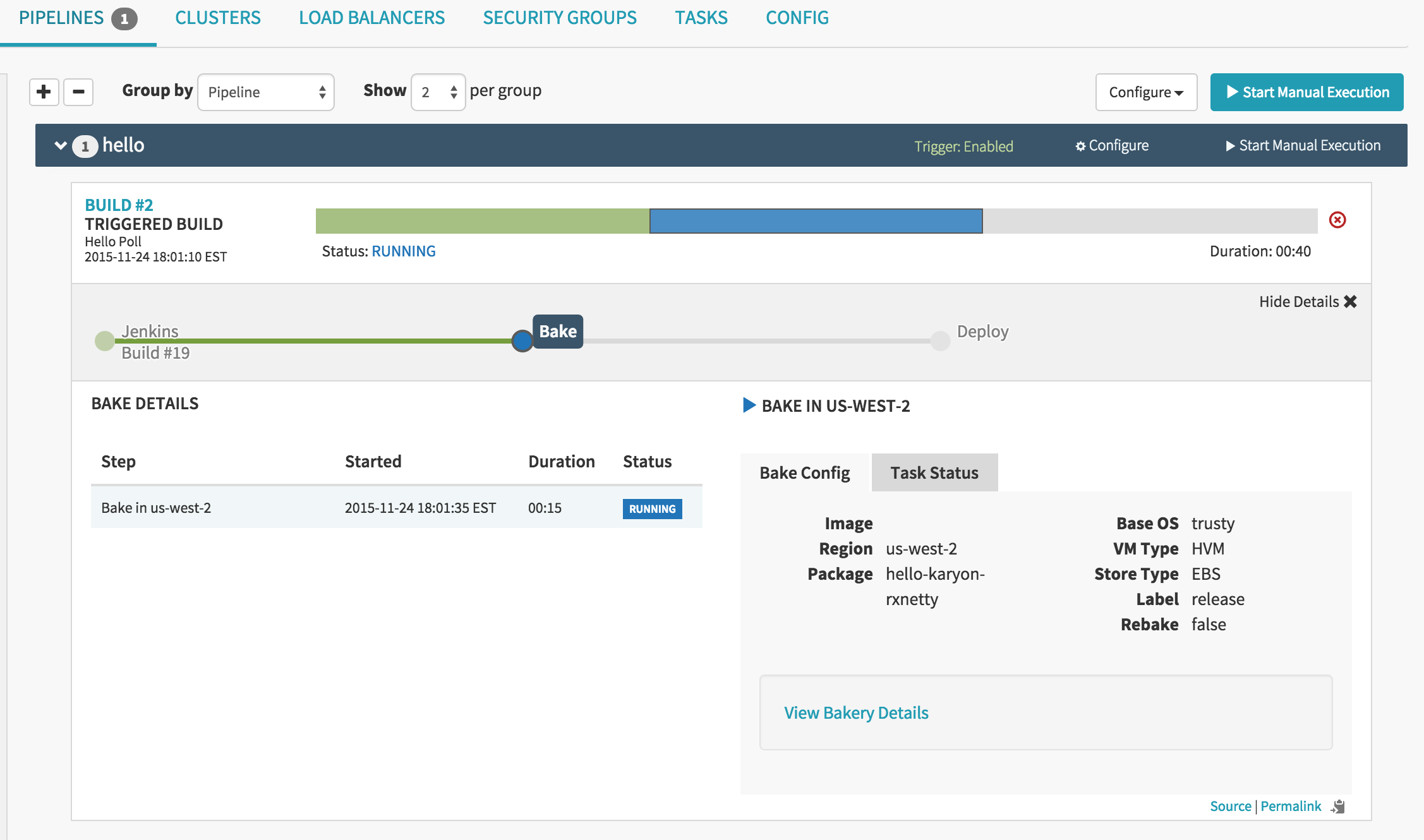
Spinnaker is using the “infrastructure-as-code” concept, also. All pipelines are also represented by yml files. The UI is completely optional and the API that runs behind the scenes is fully open for everybody to call (if such flexibility is needed).
The final step if of course to make sure that the application is actually running once deployed. No guesswork is needed here. Spinnaker has native support for the API of all major cloud providers (Google, Azure, Amazon, Openstack etc.) and can query the status of clusters from the same interface used for deployment.
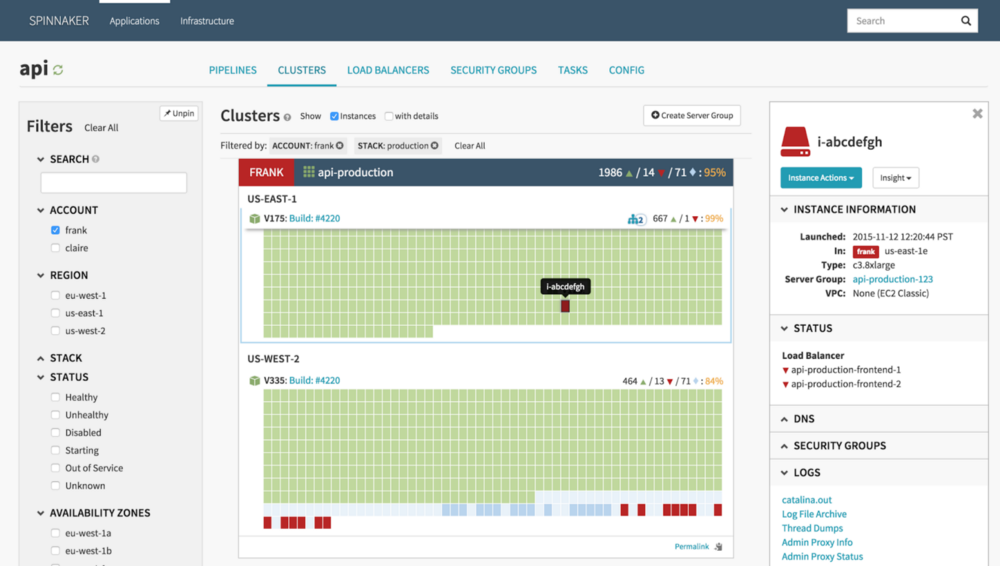
Therefore, it is no longer necessary to visit the cloud console of your cloud provider to see what is happening. You can resize, delete or even create completely new clusters from Spinnaker itself.
It should be clear now that Spinnaker can handle all phase of cloud development with a single platform.
Spinnaker and Kubernetes
The icing on the cake, is that Spinnaker has native support for Kubernetes. Kubernetes support was added by Google itself and it is an integral part of the basic Spinnaker distribution.
Spinnaker handles Kubernetes like any other cloud provider. It can read the health of Kubernetes cluster and perform deployments using the same calls as any other external Kubernetes tool. In fact, Spinnaker augments the basic Kubernetes deployment capabilities by offering deployment strategies not offered in Kubernetes yet.
For a detailed description on Kubernetes support see the documentation.
Conclusion
We hope that with this article you have now understood what is the concept behind Spinnaker, how it works with other tools and what are the benefits compared to existing solutions.
Go back to contents, contact me via email or find me at Twitter if you have a comment.