Spinnaker Is Not a Build Server (And Other Misconceptions)
16 Oct 2017This post was originally published at the Armory Blog. Reposting here since it is not available there any more.
Introduction
Deploying software in a predictable and deterministic way has never been more important than now. Companies that stay in the old model of deploying an application every 3 or 4 months will soon be left behind by their fast moving competitors.
Today, most companies aim for a deployment cycle that takes less than a day, while well-disciplined companies are already deploying every few minutes.
Quick quiz: Try to find the stage your company is at using the following chart!
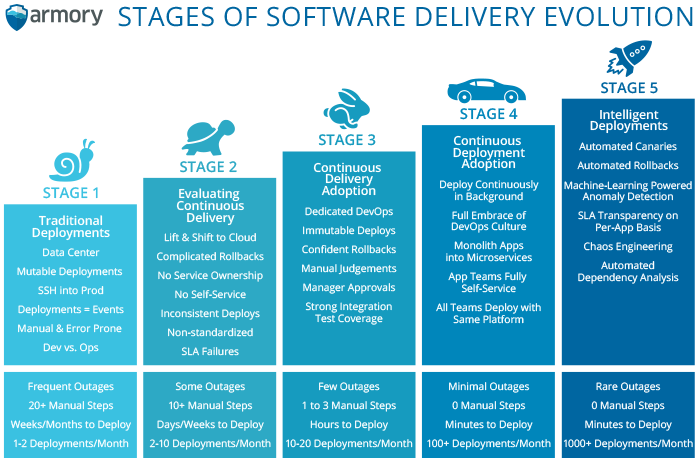
Consider yourself lucky if your company is at stage 3 (or above). Ideally you should aim for stage 5.
The new Cloud/Container landscape
In theory, software deployments have become easier over the last years. A Renaissance in the software delivery model has started with the introduction of the public and private cloud and more recently with the adoption of containers as a single deployment unit.
In practice however, the landscape is muddy and blurry. Several vendors have scrambled to adapt their old data-center tools for the dynamic nature of the cloud, with questionable success. New startups have appeared that embraced containers (i.e. Docker) as the central basis for the whole software lifecycle. And of course no deployment discussion would be complete without Kubernetes. Kubernetes has taken the software world by storm and seems like an unstoppable force that focuses on standardizing deployments by orchestrating containers.
In this muddy landscape, a new contender has appeared – Spinnaker. Unlike other new products however, Spinnaker is not a startup product. It was open-sourced by Netflix in 2016 after being used internally in production. Spinnaker comes with several unique features that can change completely the way deployments are handled within your company.
Spinnaker is more than a CI tool
First things first. Spinnaker is not a build server. It was never designed that way. While in theory Spinnaker could implement its own service that acts as a build server, there is no need to do this. Spinnaker takes advantage of the existing Jenkins ecosystem and uses Jenkins behinds the scenes.
Spinnaker has full support for controlling a Jenkins instance via its native API. Starting and monitoring Jenkins jobs is transparent to the Spinnaker user. This means that rather than designing a complete build server from scratch , Spinnaker takes advantage of your existing Jenkins installation with all its assorted plugins and existing configuration.
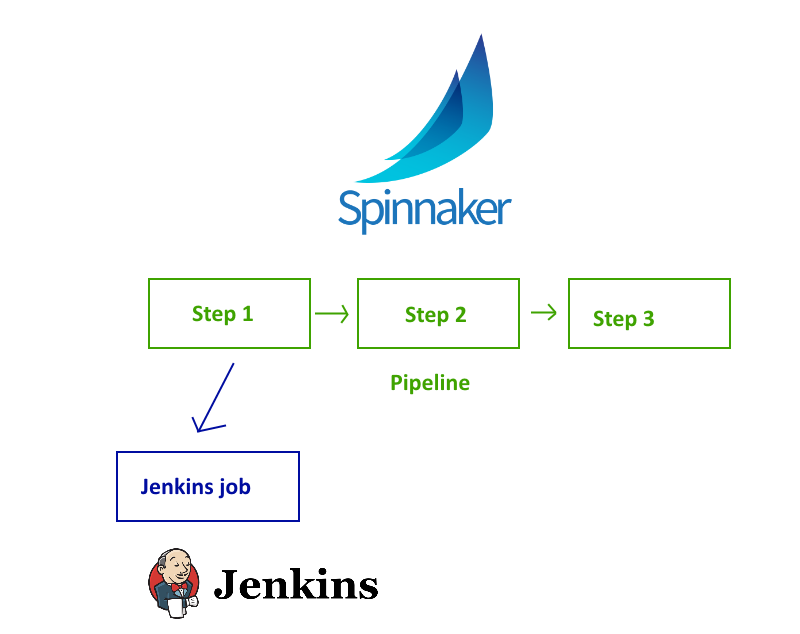
Now that we established that some parts in a Spinnaker pipeline actually correspond to Jenkins Jobs, you might be wondering what are the extra steps that Spinnaker offers.
Spinnaker was designed from the ground up to be a cloud deployment tool combining Continuous Integration and Continuous Delivery. This means that instead of just executing arbitrary tasks, it has first class support for cloud concepts.
If you look at all the build servers in the market (Jenkins, GoCD, CircleCI, Codeship etc) you will realise that the basic modeling concept in all of them is a task and a pipeline (that connects multiple tasks together). What happens inside a task is not modeled at all and can be any combination of existing scripts. By default, the only capability a build server has is compiling code by calling the build system of your application. Any other action requires custom scripting or some form of plugin.
Spinnaker on the other hand has a richer deployment model that clearly defines
- Individual servers
- Server groups
- Load balancers
- Network/security groups
- Images and applications
- Deployment strategies
All these concepts are already defined within Spinnaker, and no custom scripting is needed to activate them.
Thus, where a basic CI (build server) tool contains only the most basic task which is executing a command (or list of commands), Spinnaker offers built-in support for doing things such as creating load balancers, resizing clusters and rolling back applications. Essentially Spinnaker works on a much higher abstraction level than most CI tools.
All these Spinnaker capabilities are present in other tools (e.g. Terraform and Cloud formation) but these must be linked with custom glue code inside the steps of a build server. Even then, Spinnaker (because of its native support for various cloud providers) can monitor the status of a cluster and manage it, from within the same dashboard. Spinnaker also combines the ability to monitor and deploy to different cloud providers at the same time.
Spinnaker is essentially a complete deployment solution that combines the capabilities of multiple existing tools (plus custom glue code) into a single and cohesive package.
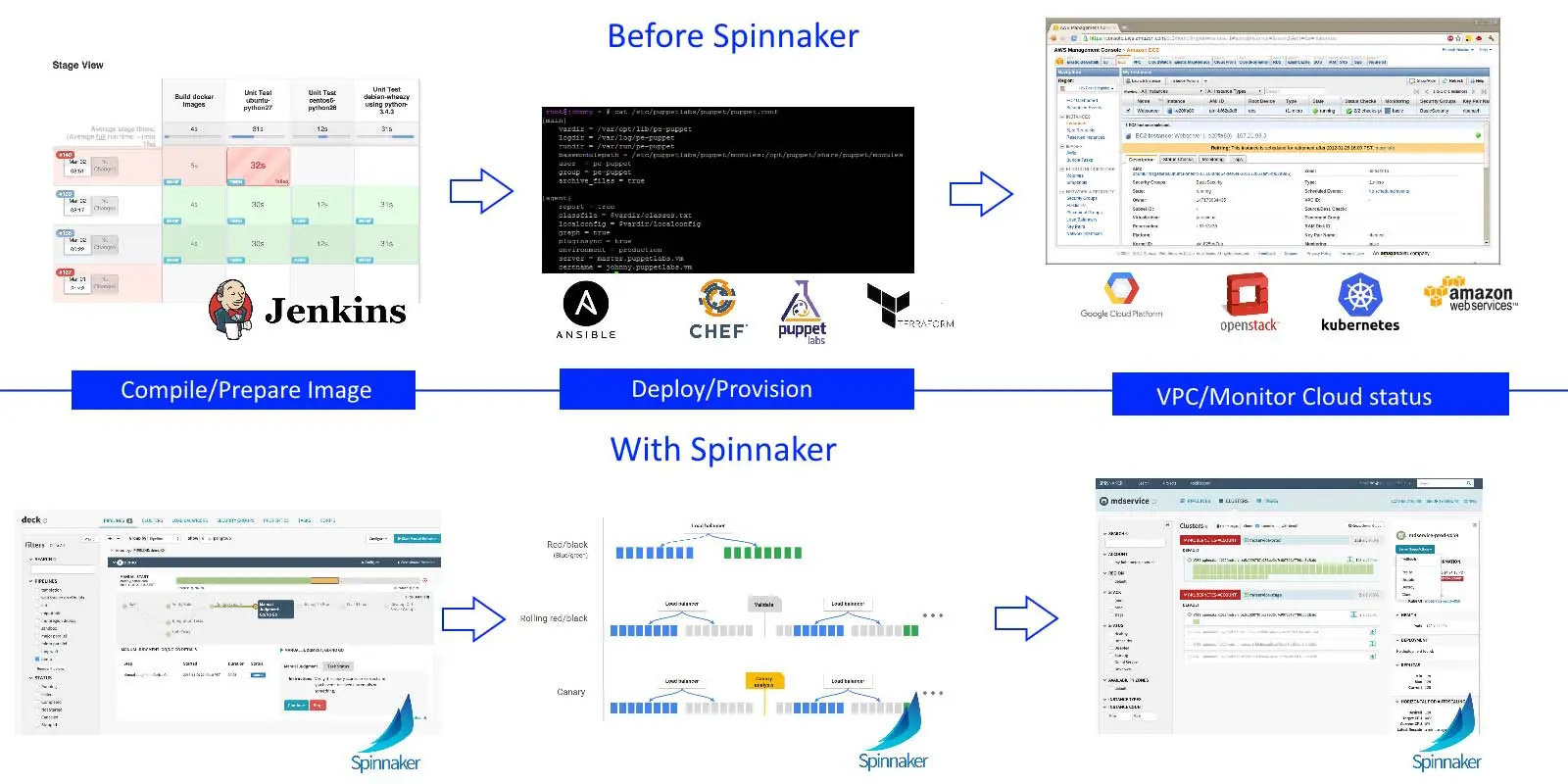
The following table shows how Spinnaker can be roughly compared to existing tools.
| Tool | Code compilation | Built-in cloud deployment | Built-in cloud management |
|---|---|---|---|
| Spinnaker | Yes (via Jenkins API) | Yes – Cloud agnostic | Yes – Cloud agnostic |
| Jenkins | Yes | No | No |
| CircleCI | Yes | No | No |
| GitlabCI | Yes | No | No |
| GoCD | Yes | No | No |
| TravisCI | Yes | No | No |
| Codeship | Yes | No | No |
| Terraform | No | Yes | No |
| Cloud Formation | No | Yes – only AWS | No |
| AWS console | No | No | Yes – only AWS |
| Google Cloud Console | No | No | Yes – only Gcloud |
Spinnaker versus configuration management tools
This comparison is really really easy. All the configuration tools that exist today (e.g. Puppet, Chef, Ansible) were initially created for the world of datacenters where there is an 1-1 mapping between a machine and a bare-metal server. The original purpose of these tools was to keep a fleet of machines up-to-date by continuously updating their configuration. We call this pattern mutable infrastructure.
Mutable infrastructure makes sense when all you have is a real server that needs to be running at all times. Unfortunately, with the appearance of cloud infrastructures this is not the most optimal strategy anymore. Virtual machines change completely the process, as “servers” are now an abstract concept that can be dynamically launched and teared down in a matter of minutes.
Containers took this dynamic nature even further by allowing developers to spin up an application in seconds rather than minutes.
Mutable infrastructure suffers from two major problems:
- Configuration drift
- Rollbacks are hard.
Configuration drift is the well-known problem where two machines that are supposed to have the same configuration are not really similar. The problem comes from manual changes that happen to the machines outside the control of the configuration tool. These manual changes start in the most innocent way, but can quickly become a source of frustration and even the cause of failed deployments.
The second problem is that rollbacks are next to impossible in a mutable infrastructure. Once the new configuration is deployed, the old application is gone. If something is wrong with the new application and a rollback is needed, it is up to the developer to explain how the configuration tool can bring the old configuration back. This process can easily become a nightmare, especially if downtime must be kept to a minimum.
Mutable infrastructure was a good fit for bare-metal servers. In the context of virtual machines and containers there is now a better way to handle deployments!
Spinnaker is based on immutable infrastructure. Immutable infrastructure defines that once a server is deployed it stays that way and never changes again. A new version of the application will be installed to a completely new server. This means that both problems of mutable infrastructure go away
- There is never a configuration drift (by definition)
- Rollbacks are very easy
Because the servers are never touched after the initial deployment, the configuration of every server is exactly the same as every other one. Even if some developer makes a change to a server manually, the next time the application is deployed, all servers will start from the same initial state.
Because a new server is created each time, the old server can be kept alive for a brief period of time. This allows for rolling deployments (a.k.a blue/green) where client traffic is redirected to the new servers (typically via a load balancer) while the old servers are still on standby.
If the new version of the application is not deemed to be healthy, then the rollback is a one-step-process of redirecting customer traffic back to the old servers.

This is a huge competitive advantage that Spinnaker offers as a built-in feature without any extra scripts or glue code. At the time of writing there is no other open source tool in the market that offers this capability.
A related deployment pattern is the use of canaries. This is a similar pattern with blue-green deployments, where only a limited amount of servers (or even just one) is created for the new version of the application. Once the canary is deemed healthy, then all servers are created for the new application. If the canary shows a problematic release, it is just deleted and removed from the server pool.
Here is the respective comparison table:
| Tool | Deployment Paradigm | Configuration drift problems | Blue/Green deployment | Canary deployment | Rollbacks |
|---|---|---|---|---|---|
| Spinnaker | Immutable infrastructure | Not possible | Built-in | Built-in | Instant – pain free |
| Puppet | Mutable infrastructure | Present | No | No | Very hard |
| Chef | Mutable infrastructure | Present | No | No | Very hard |
| Ansible | Mutable infrastructure | Present | No | No | Very hard |
| Salt | Mutable infrastructure | Present | No | No | Very hard |
| CFEngine | Mutable infrastructure | Present | No | No | Very hard |
Spinnaker and Kubernetes
Containers in the form of Docker solve the problem of having a single deployment artifact that is self-contained and described in a well-known image format. Deploying docker applications directly by hand and managing them individually, is certainly possible for several use cases.
In most common real world scenarios and especially when the number of containers is really big, the need for container orchestration arises so that a dedicated tool can monitor, deploy and even restart containers in an automatic way.
There are currently multiple orchestration solutions in the market with the leading one being Kubernetes. Other alternatives are Docker Swarm, Hashicorp Nomad and Mesos/Marathon.
Kubernetes is a solid solution for performing deployments and managing containers in large clusters, but an important thing to remember is that it only handles the runtime aspect for your infrastructure. The role of Kubernetes starts from deploying a docker container that already exists in a Docker registry. Kubernetes knows nothing about compiling code or building containers.
This is not a bad thing, as Kubernetes was designed this way, to focus only on the runtime of an application. The important question is what tool can be used for the other half of the picture.
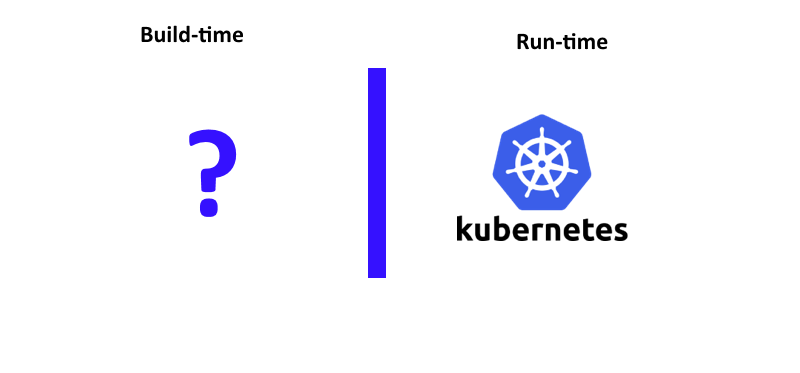
Spinnaker has the answer here as well. Google has implemented native Kubernetes support within Spinnaker. Spinnaker has direct access to Kubernetes ReplicaSets via the official API. This means that Spinnaker has the ability to manage Kubernetes Pods and expand/shrink Kubernetes clusters as any other cloud provider.
This makes Spinnaker the perfect match to a Kubernetes cluster. Each tool is responsible for what it does best. Spinnaker takes care of the build-time concerns of the application, while Kubernetes is handling the runtime. Because Spinnaker has native support for Kubernetes pods, it is actually possible to monitor a Kubernetes cluster from within the Spinnaker dashboard, further strengthening the position of Spinnaker as a unified deployment solution.

Notice that apart from Kubernetes, Spinnaker has native support for AWS, Azure, Openstack and Gooogle cloud.
Conclusion
After reading all the comparisons above, you might be wondering what tools are actually competitors to Spinnaker. The answer is none! At the time of writing there is not a single tool that:
- Combines compilation, baking, deployment and cloud management in a single dashboard
- Is cloud agnostic and can work with Amazon Web services, Google Cloud, Azure, Openstack
- Follows the immutable infrastructure principle
- Has native support for deploying to Kubernetes clusters
- Has built-in support for blue/green deployments allowing for zero-downtime upgrades
- Has built-in support for canary releases so that bad deployments can be identified early
- Has built-in support for software rollbacks
- Is Open Source
- Is used in Production environments by major companies (Netflix, Google, Target etc).
Take a look back to the “stages” diagram introduced at the beginning of the article. Don’t stay in the lower levels! Aim for the top.
Go back to contents, contact me via email or find me at Twitter if you have a comment.